How big should my input stream buffer be?
In Sun's current implementation, the default buffer size for a
BufferedInputStream is 8K. On certain systems at least, this appears to
be about the "point of diminishing return" at which increasing the buffer size
does not improve either overall read time or CPU usage.
(And after all, Sun probably chose this size for a reason!)
In other words, unless you've some reason not to, you may as well
stick to the default.
The size of the read buffer affects both overall time taken to read the data
plus the CPU time used. As a rule, both diminish as buffer size
is increased, but overall time tends to plateau quickly as buffer
size is increased. Even at the point where increasing the buffer size gives no
gain in overall time to read the data, CPU time can continue to diminish. In other
words, a large buffer size will probably benefit applications that are performing
simultaneous reading and processing of data, but won't bring
much benefit to single-threaded applications that must wait for the data before
proceeding.
The graph below shows some example measurements of elapsed and CPU time
as buffer size is increased. In each run of this test, the contents of 10 files each of
50MB in size were read in via a BufferedInputStream of the given size1.
(In this case, the test system was a 2GHz uniprocessor Windows system with a
standard 7,200 RPM hard drive.)
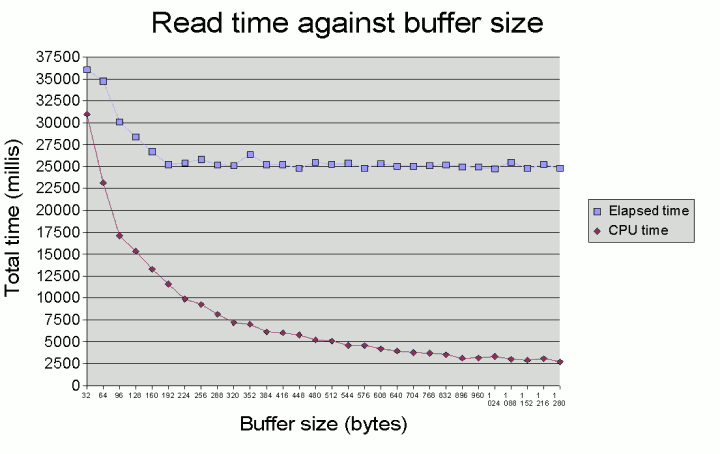
In this test case, overall read time plateaus at a buffer size of around
192 bytes. However, at this buffer size, we burn aroun 25% of the CPU.
Beyond this buffer size, CPU usage continues to decrease even though overall
read time remains more or less constant. At a buffer size of around 1K,
we use in the order of 10% of the CPU while reading through the file.
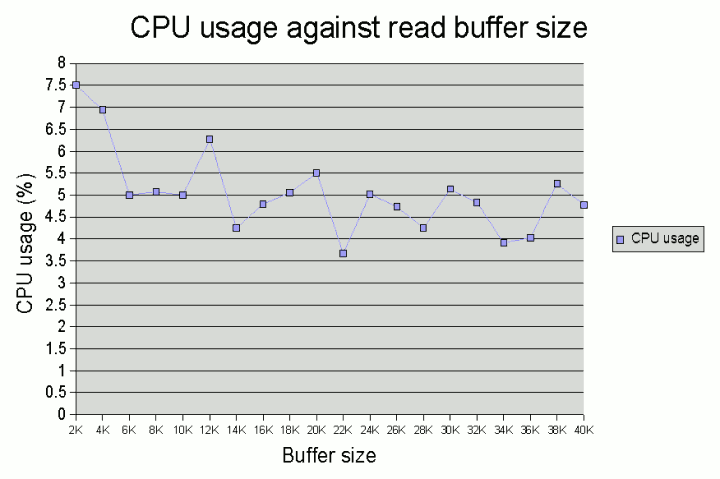
Effect of larger buffer sizes on CPU usage
In our test case here, there appears to be a slight benefit in terms of
CPU usage when the buffer size is made a little larger than 1K. However, beyond
around 8-10K, CPU usage settles to around 4.5-5% (although the measured
CPU usage fluctuates a little from run to run).
1. This size was chosen to try and minimise the effect of OS buffering on
read performance. In the test configuration, the OS appeared to buffer up to
around 100MB of data. So the overall 500MB of data meant that at the start
of a run, there was probably little or no useful data in the file system caches
left behind by the previous run.
If you enjoy this Java programming article, please share with friends and colleagues. Follow the author on Twitter for the latest news and rants.
Editorial page content written by Neil Coffey. Copyright © Javamex UK 2021. All rights reserved.