Transforming data to improve Deflater performance
DEFLATE is a generic algorithm which on the whole works quite well with
various types of data. In particular, it can typically compress textual data (including
'pure' human language text and text-based structured formats such as HTML and
XML) to around 25-30% of its original size.
Of course, deflate and Deflater provide a generic algorithm
designed to cope reasonably with "typical" data. But on its own, Deflater
doesn't know about specific properties of your data that might help it
achieve better compression. In the real world, most people don't have the time
and resources to develop a completely new compression algorithm from scratch. But
sometimes it's possible to "go halfway" and transform your data
to work better with the deflater.
Using the FILTERED or HUFFMAN_ONLY modes
The zlib library (and hence the Deflater class) allows a couple of strategy
settings beyond the default of dictionary-plus-Huffman compression:
- the FILTERED setting applies a minimal amount of dictionary lookup,
and essentially applies Huffman compression to the input;
- the HUFFMAN_ONLY applies Huffman compression to the input without
attempting any dictionary-based compression at all.
So when are these options useful? Well, occasionally we can get our data
into such a format that certain bytes are predominant in the stream, but
with few "repeating patterns".
Example: compressing text
We'll look here at the specific example of compressing what is basically "ordinary text"
in human languages. Specifically we'll look at some XML files containing some minimal markup and
slabs of text in common European languages written in
Roman script: English, French and Spanish. These all have the characteristic that:
(a) they use a relatively small alphabet;
(b) the probability of a given letter is highly uneven;
(c) the probability of a given letter is somewhat dependent on the previous letter.
The fact that these are XML files means that in addition to letters of the alphabet,
the data actually contains a few extra markup symbols, but we'll treat the problem as though
we were just dealing with "pure" text. The approach still works quite well, and compressing
XML files is a useful and common thing to want to do.
As mentioned previously, throwing text through a bog-standard
Deflater actually performs reasonably. So if you have absolutely no development time
available and need to compress text, you can typically get it down to 25-30% of its
original size "for free". But it turns out that with a little bit of extra judicious processing,
you can squeeze another few per cent out of the Deflater.
We essentially rely on some knowledge about the data that the Deflater
doesn't have: namely that– and the way in which– the probability of a given
letter depends on what the previous letter was. As an example, the graph below shows
the frequency of various 'next letters' following the letter 't' in a sample of
text (in this case the language was French).
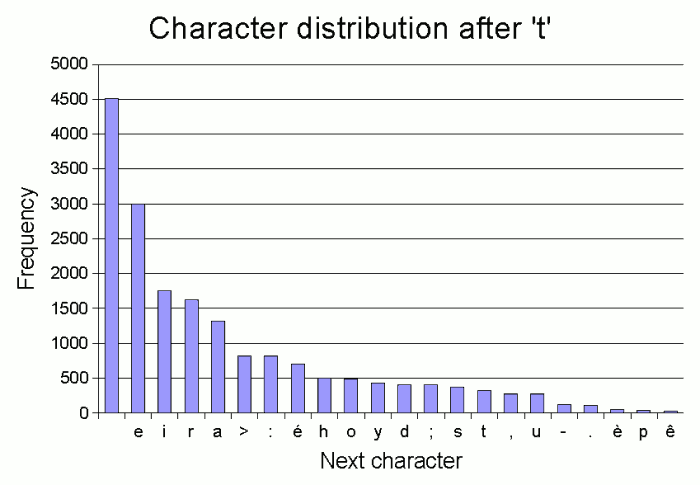
Eyeballing the graph, we see that frequency generally tails off pretty sharply
after the first couple of letters. The second-most-frequent letter is more or less
half as frequent as the most frequent, and a similar relationship exists between
the next pair. After that, we don't quite have the perfect negative-powers-of-two
distribution that would be the optimum case for Huffman coding. But we do
have a graph that starts off with halving frequencies, and then frequencies are
pretty low in any case after that. It turns out that if we consider the distribution
of "next letters" after most letters, they have a graph quite similar to that for
't'.
In other words, there's a transformation that we can apply to our data that
makes it a fairly good candidate for Huffman encoding. We turn our data into a list
of bytes where each byte represents the index of the given character in an
ordered list such as in the X axis of the graph above. In other words, if the
last byte in the stream was a 't' and the next byte is a space, we write 0 because
a space is the 0th most frequent character after a 't'; if after a 't' we have an
'e' we write 1, etc.
We end up with a data stream that hugely favours low numbers, in particular
sequences of consecutive 0s. This pattern of data then compresses well with the
FILTERED option of Deflater. In my test sample of text extracted
from HTML pages containing news articles1, I got the following
improvements in compression ration over "standard" deflation:
| Language | Improvement in compression |
|---|
| English | 11.9 % |
| French | 20.4 % |
| Spanish | 13.0 % |
Of course, it's also possible that these improvements reflect other
features of the text sources in question other than the language. But there
does seem to be a general trend: if we're prepared to put in a bit of extra
effort, we can improve on the standard Deflater at relatively low
cost in terms of development time. It's a fairly simple task to write a routine
to throw the frequencies of character-given-last-character
into an array and then output indices from this array– certainly
a much simpler task than writing and debugging the Huffman coding routines
(or other compression routiens) yourself...!
Of course, this compression technique relies on "shared knowledge" in the form
of the frequency tables which would need to be transmitted along with the data.
However, these can be got down to around 3K in the typical case, so if you're
transmitting a reasonable amount of data there is definitely still a saving.
1. You'll see from the graph that in fact, my text extraction process
wasn't perfect, and some basic HTML tags remain in the text (notice that the
end-of-tag character figures in the statistics). But if anything, this suggests that
"cleaner" text would actually compress a little better using this technique.
If you enjoy this Java programming article, please share with friends and colleagues. Follow the author on Twitter for the latest news and rants.
Editorial page content written by Neil Coffey. Copyright © Javamex UK 2021. All rights reserved.