Secure hash functions in Java (ctd)
The Java cryptography library provides various secure hash functions or message digest algorithms out of the box.
On the surface, they are simple to use. For example, we can calculate the MD5 hash of a byte array in Java
using the java.security.MessageDigest class. The Java code for computing the hash would look something like this:
byte[] data = ....
MessageDigest md = MessageDigest.getInstance("MD5");
md.update(data);
byte[] hash = md.digest();
or to calculate the SHA-1 hash, we can simply specify that algorithm:
MessageDigest md = MessageDigest.getInstance("SHA-1");
...
The resulting hash is also a byte array. But it will be much smaller (a few bytes, depending on the specific algorithm chosen)
than the original data. How to choose between MD5, SHA-1 etc is a more complex issue that we will look at in more detail below.
Use of secure hashes or message digests
As mentioned in our introduction to secure hash functions, the purpose of a
message digest is to take some data of arbitrary length (and potentially this could be a large file, for example) and
produce a hash or "fingerprint" of that data. The idea, in principle, is that:
- no two different pieces of data, of any length, will ever result in a collision (two distinct pieces of data having the same hash);
- given a particular hash, we cannot retrospectively construct some data that would result in that
fingerprint: we need to know "what the data originally was".
Clearly it cannot be literally true that every possible combination of bytes in the universe will produce, say,
a unique 16-byte hash value. The science of secure hashes is to choose a hash size and algorithm so that it is true
in practice for the purpose at hand. For example, it is generally true in practice that given the MD5 hash of
a file, you will not stumble upon another file with the same hash. (It is important to note that by "in practice" here, we mean
"we can calculate the chances mathematically and are happy that the probability is negligible".) In reality,
weaknesses have been discovered in various standard hash algorithms
such as MD5 that mean that the second of these assumptions is not strictly true.
But given a choice of algorithm, if we can guarantee that these conditions are true to all intents and purposes, then this
means that message digests are useful in situations such as:
- data matching and syncing: we want to ensure that a 10GB file on one machine matches that on another.
Before streaming the entire 10GB file across the network, we can send the few bytes of the hash, and only stream the
entire file if the machine at the other end indicates that its hash of the file does not match;
- data integrity checks: when decompressing or decrypting a file, we might want the client to be able
to check "was this the original data"; if, at the time of compressing or encrypting the data, we append a secure hash of
the original data, then when the client decodes it, it can calculate a hash of the resulting data and check that it matches
the hash originally calciulated at the time of compression/encryption.
- data security/authentication checks: for example, we can check that the hash of a password input by the user matches
the hash stored on a database, without having to store the actual password. (And conversely, it is in principle impossible to take
the hash and deconstruct the passowrd.)
Checking that a hash matches
In Java, to check that a given hash that we have received matches one that we have just calculated,
then we can use the MessageDigest.isEqual() method, passing in the two
byte arrays representing the hashes (we could also use Arrays.equals()—
it really is just a byte-by-byte comparison!).
Which hash should I use? Characteristics of various secure hash algorithms
In principle, you can see that the MessageDigest class has a similar
pluggable architecture to the Cipher class: we pass
in the name of the algorithm we want to use, and the security architecture finds
a suitable provider that can fulfil that request. In practice, there are a handful
of viable options which most JDKs will support, including MD5 and several SHA variants.
(SHA-1, SHA-256, SHA-384 and SHA-512).
If you're just looking for the answer to the question which hash function
should I use in Java? without too much philosophy, then the answer will almost
certainly be SHA-256. Below we'll give some background as to why.
Performance of hash algorithms
Figure 1 shows the relative performance of these different hash algorithms.
As we'll discuss below, to some extent, there's a tradeoff between security and
performance, although it turns out that the more secure hashes are in fact
"fast enough" for most applications.
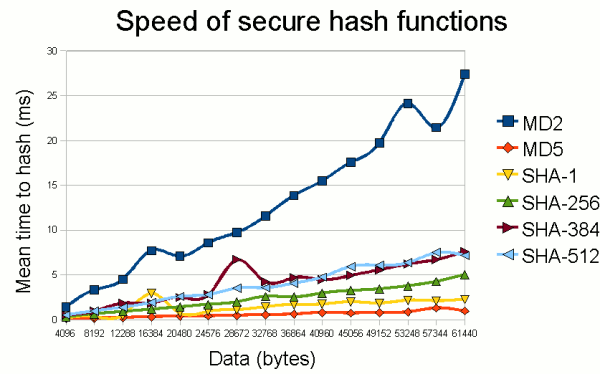
Figure 1: Performance of standard secure hash functions.
(Timings from a 2GHz Pentium running Java 6 under Windows XP;
each point is actually the mean of 20 measurements.)
As can be seen, the only hash algorithm (of those available by standard in Java)
that really stands out from the rest is MD2. The fact that it is orders of
magnitude slower than other hash functions will usually put it out of the running
given that it is only 128 bits in width (see below), now considered unsuitable
for any application where true security is required.
Other characteristics
In the following table, we summarise some more general characteristics of the
various hash algorithms available by standard in Java.
MD2
MD2 is one of the earliest hash functions developed by Ron Rivest at RSA Security.
To date, no full attack on MD2 has been published, but attacks have been
published on the compression function (one of the components of the
hash algorithm). Aside from this partial attack, the main reason for avoiding
MD2 is that it is extremely slow compared to other algorithms (see Figure 1).
It is a 128-bit hash, meaning that we would expect to find a collision
by chance after hashing 264 sets of data. Many consider this unacceptably low
for new applications, considering they may need to cope with the volumes of data that people
will be working with several years into the future.
MD5
MD5 is a later hash function developed by Ron Rivest. It is one of the most common
hash algorithms in use today. Like MD2, it is a 128-bit hash function but, unlike its
predecessor, it is one of the fastest "secure" hash functions in common use, and
the fastest provided in Java 6.
Unfortunately, it is now considered insecure. Aside from the relatively small hash size,
there are well-published methods to find collisions analytically
in a trivial amount of time. For example, Vlastimil Klima has published a
C program to find MD5 collisions
in around 30 seconds on an average PC. If you need security, don't use MD5!
Although insecure, MD5 still makes a good general strong hash function due to
its speed. In non-security applications such as finding duplicate files on a hard disk
(where you're not trying to protect against the threat model of somebody deliberately fooling
your system), MD5 makes a good choice.
SHA algorithms
SHA (Secure Hash Algorithm) refers collectively to various hash functions
developed by the US National Security Agency (NSA). The various algorithms are based
on differing hash sizes and (in principle) offer corresponding levels of security:
| Algorithm | Width | Characteristics/comments |
|---|
| SHA-1 | 160 bits | Design based on MD4/MD5. After MD5, probably the next most commonly used hash function. Insecure against an adversary with considerable resources, but otherwise moderately secure in the short term. A known attack can find collisions with 263 complexity (whereas by chance, we'd expect 280). NIST considers this "plainly within the realm of feasibility for a high resource attacker" and has mandated that federal agencies withdraw use of SHA-1 for certain purposes by 2010 (NIST, 20061).
Depending on the expected confidentiality lifetime of data, new applications should probably avoid SHA-1 if they can, although there is no publicly known attack that is practical in the short term. |
| SHA-256 | 256 bits |
Secure by current knowledge. The best partial attack I'm aware of is a reported attack on 24 of the 64 rounds of SHA-256 (Sanadhya & Palash Sarkar, 20082) which the authors say "do not threaten the security of the full SHA-2 family".
Note that SHA-384 is a waste of CPU time: it performs the same calculations as SHA-512 and then disregards some of the bits.
|
| SHA-384 | 384 bits |
| SHA-512 | 512 bits |
Summary of SHA algorithms.
Conclusion
The above performance combined with the general security characteristics mentioned above mean
that in practice, most applications will use SHA-256. It is really the only algorithm
with sensible performance while still being secure at present.
The fact that there are now few viable hashing algorithms, and the most viable already has partial
attacks, has made NIST sit up and take notice. They are running a
public hash algorithm competition
(similar to that which chose AES as the encryption standard) to chose the third generation of
Secure Hash Algorithm (SHA-3). In 2011, the competition is now in its
third round, consisting of a year dedicated to
"public comment" of the 5 shortlisted finalists.
The winner is to be chosen in 2012.
Update October 2012: The SHA-3 winner has now been chosen. This page will be updated shortly with more information.
1. See NIST (2006), NIST Comments on Cryptanalytic Attacks on SHA-1.
2. Sanadhya, S. K. & Sarkar, P. (2008), New Collision Attacks against Up to 24-Step SHA-2 in Progress in Cryptology - INDOCRYPT 2008, Springer.
If you enjoy this Java programming article, please share with friends and colleagues. Follow the author on Twitter for the latest news and rants.
Editorial page content written by Neil Coffey. Copyright © Javamex UK 2021. All rights reserved.