Java performance on Apple Silicon (M1) vs Intel architecture
This page shows some initial performance comparisons between Java running on Apple's M1 chip versus
Intel x64 architecture. As well as some "raw" performance comparisons, we show some differences
in threading behaviour.
Systems compared
In the tests below, we compare Intel and M1 builds of Azul JDK 11 (build 11.0.9.1, the latest available
at the time of performing the tests). The specific hardware used for the comparisons is as follows:
| | Intel | Apple Silicon |
| Machone | iMac, Late 2015 | MacBook Pro (2020) |
| CPU | Intel i7, 4GHz | Apple M1 |
| Cores | 4 Core hyperthreading | 8 Core:
4 x 3.2GHz "high-performance"
4 x 2GHz "high-efficiency"1 |
| RAM | 32 GB | 8 GB |
1. Clock speeds and other CPU usage details are those reported by the powermetrics utility
during the benchmark test runs described here.
Hyperthreading and non-uniform cores
An interesting feature of both the i7 and the M1 is that they present themselves as 8-core processors
(i.e. Runtime.getRuntime().availableProcessors() reports 8 "processors"). Yet in reality, on both
of these CPUs, only 4 of the cores are "first class citizens". In the Intel hyperthreading system,
there are 4 physical cores mapped to 8 logical cores;
multiple threads are scheduled on to the same hardware core and a given core can take
instructions from either thread depending on the availability of the required execution units.
(Thus, two execution units of a given core could be simultaneously executing operations for
instructions from different threads.) This scheme generally requires operating system support to be most
effective (for example, to ensure that two threads are not scheduled on the same physical core if another
core is available).
The Apple M1 chip has 8 physical cores, but they are split into two groups:
- the Firestorm group: 4 performance cores or P-cores, which are allowed to run at the maximum
clock speed;
- the Icestorm group: 4 efficiency cores or E-cores, which run at a maximum of two thirds of the
clock speed and have less CPU cache.
It is possible that the Icestorm cluster also makes other architectural simplifications to achieve power efficiency,
such as having a shorter instruction pipeline. This is the case with other Apple chips, e.g. the Monsoon and Mistral pipelines
of the ARMv8-A chip, for example, are reported to have pipeline depths of 16 vs 12 instructions respectively.
Benchmark: multiple worker threads performing CPU-intensive activity
In this test, a number of threads run concurrently for a fixed period of time (20 seconds in this test),
each repeatedly conducting independent CPU-intensive calculations. The thread activity start and end
times are synchronised using a CountDownLatch, so that we try to guarantee as far as possible
that the threads genuinely have the opportunity to execute the task within the measured time span.
The specific operation chosen was to repeatedly calculate the value of a random BigDecimal
raised to a random power. Counts were then taken of the number of these operations that each thread managed
to perform within the time window of the test.
Results
The results of this test are shown in the figure below. The top two lines of the graph compare the combined
throughput of all threads; the bottom two lines compare mean throughput per thread.
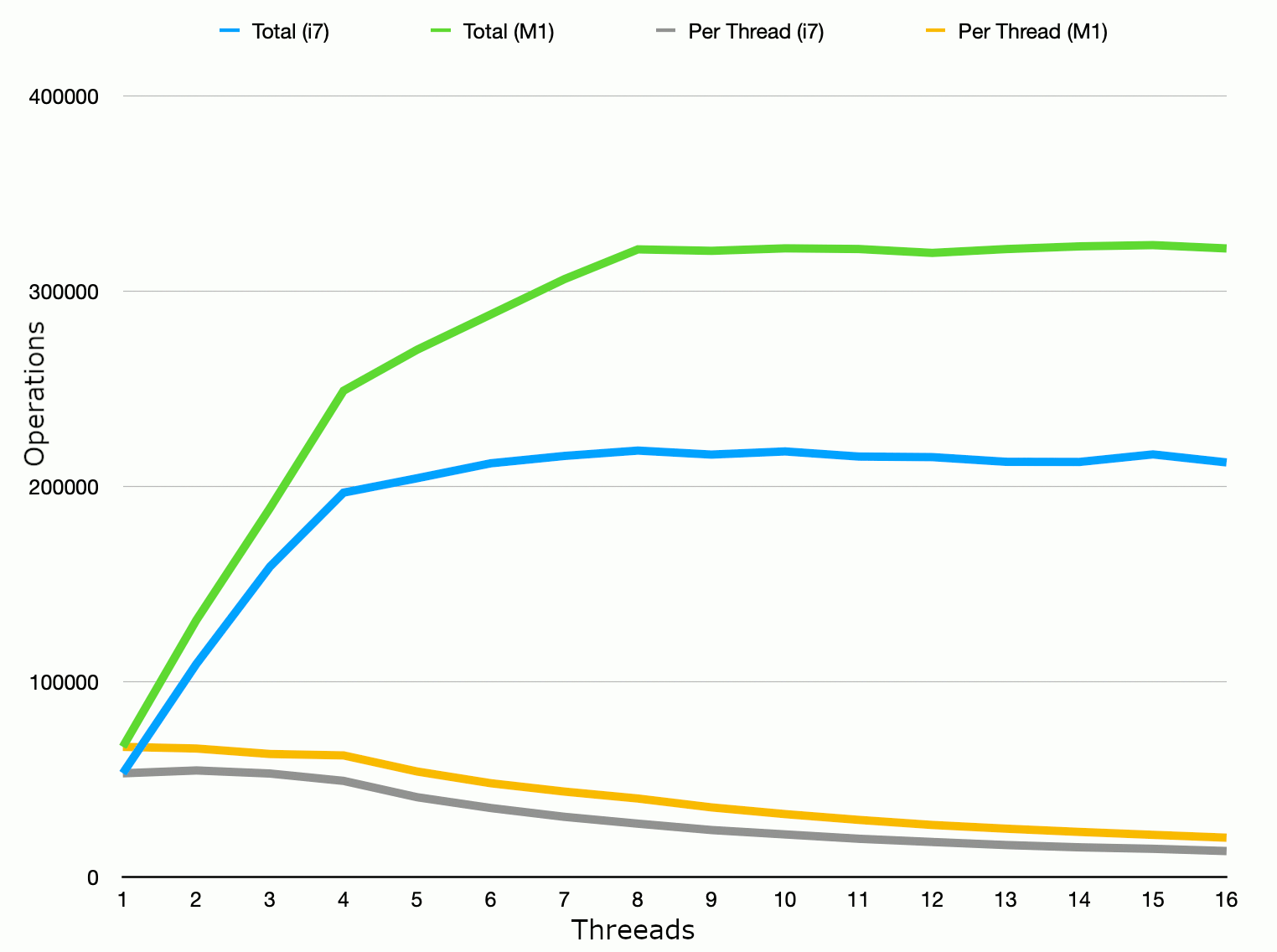
As might be expected from the description above, the overall throughput on the Intel CPU rises linearly
with the number of threads until we hit the number of hardware cores (4) and the increase in
throughput per thread matches almost exactly the single-core throughput. With 5-8 threads running
simultaneously, we know that in reality these threads will be distributed among only 4 cores and
we would not expect the same increas in throughput per thread. In this particular test, the gain from
hyperthreading is measureable but minimal compared to the increase per thread when there are no more
threads than "real" cores (compare the very shallow gradient in the blue line between threads 5-8
compared to threads 1-4). As expected, once we get beyond 8 threads, there is no benefit in adding
further threads.
The multithreading performance of the M1 follows a similar general pattern, but with two key
observations:
- in this test, the M1 has a "raw" performance (i.e. overal throughput) improvement of around 25%
over the 4GHz i7 for up to 4 concurrent threads;
- from 5-8 threads, when the additional cores used are (presumably) the "efficiency" cores,
there is a smaller additional benefit per thread, but that benefit is greater than in the
case of the i7— so that with 8 concurrent threads, the M1 outperforms the i7 by just under 50%;
- alternatively: adding 4 hyperthreaded cores gives around a 10% performance increase on the i7,
compared to around a 30% increase with the M1 "efficiency" cores; notice that this is less
than the theoretical ~60% given the 2GHz/3.2GHz clock speeds of the M1 cores.
M1 Thread to core allocation
OF course, on a modern multitasking operating system, our user programs are competing for CPU with
other programs and O/S processes. Even on a supposedly "quiet" system, we cannot realistically expect
our program to have complete occupancy of the CPU. Looking in a bit more detail at how the M1 CPU
allocates the running threads across the 4 high-performance and 4 high-efficiency cores can help
to explain the observed behaviour.
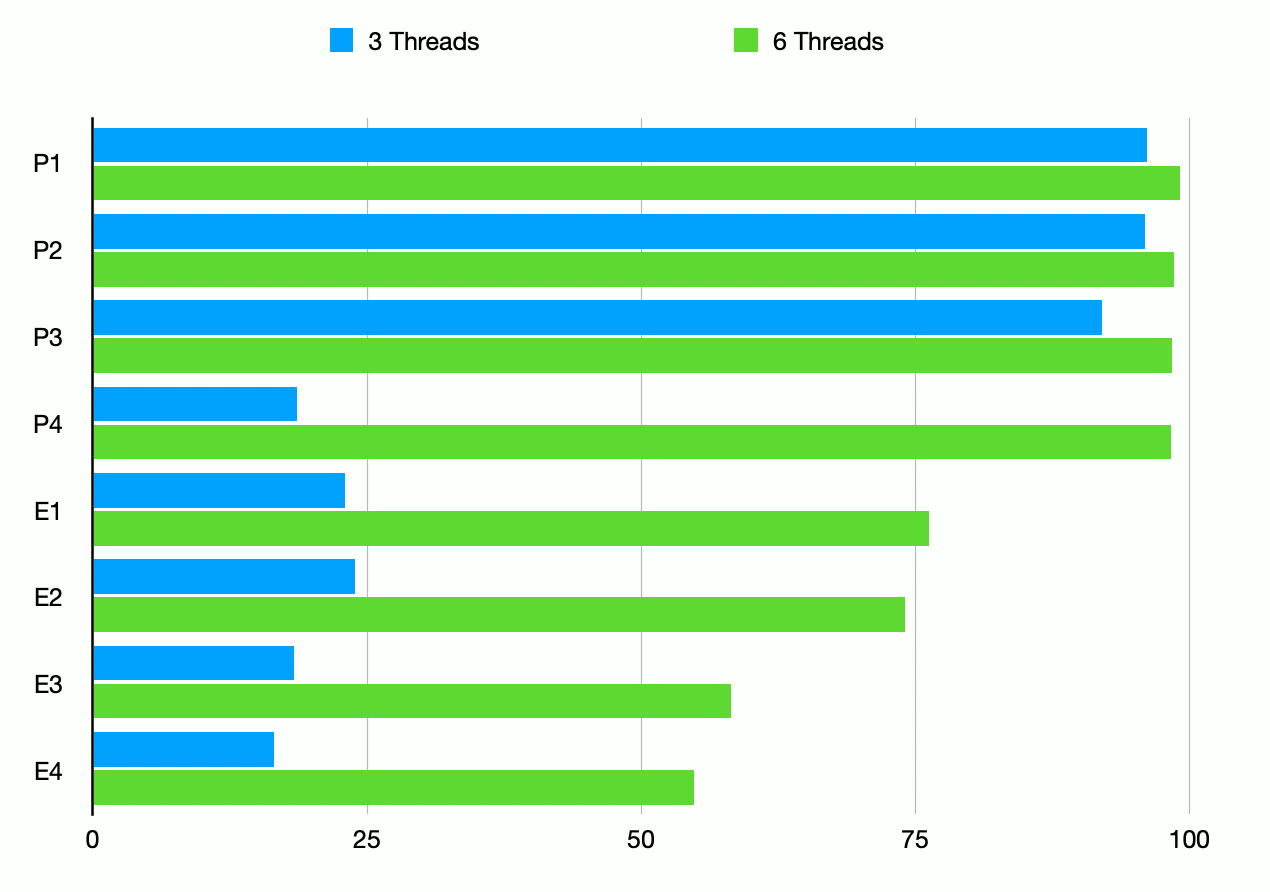
The figure above shows samples of the reportred CPU usage per core while our test is running
on 3 and 6 threads. The general pattern observed is that:
- with up to four threads, we max out the respective number of high-performance
cores (labelled P1-P4); the high-efficiency cores (labelled E1-E4) show an occupancy of around 20%,
potentially handling other
processes and potentially tasks such as garbage collection, scheduling etc);
- with more threads (cf the green series), the high-performance cores are maxed
out, while the remaining load appears to be more distributed among
the high-efficiency cores (we increase the load on two of the cores to around 75%,
while the remaining cores increase to around 50%).
(N.B. The fact that we max out n high-performance cores with n <= 4 threads does
not necessarily mean there is perfect affinity between threads and cores, of course, but it seems
we can at least model our performance expectations on the basis that this is roughly the case.)
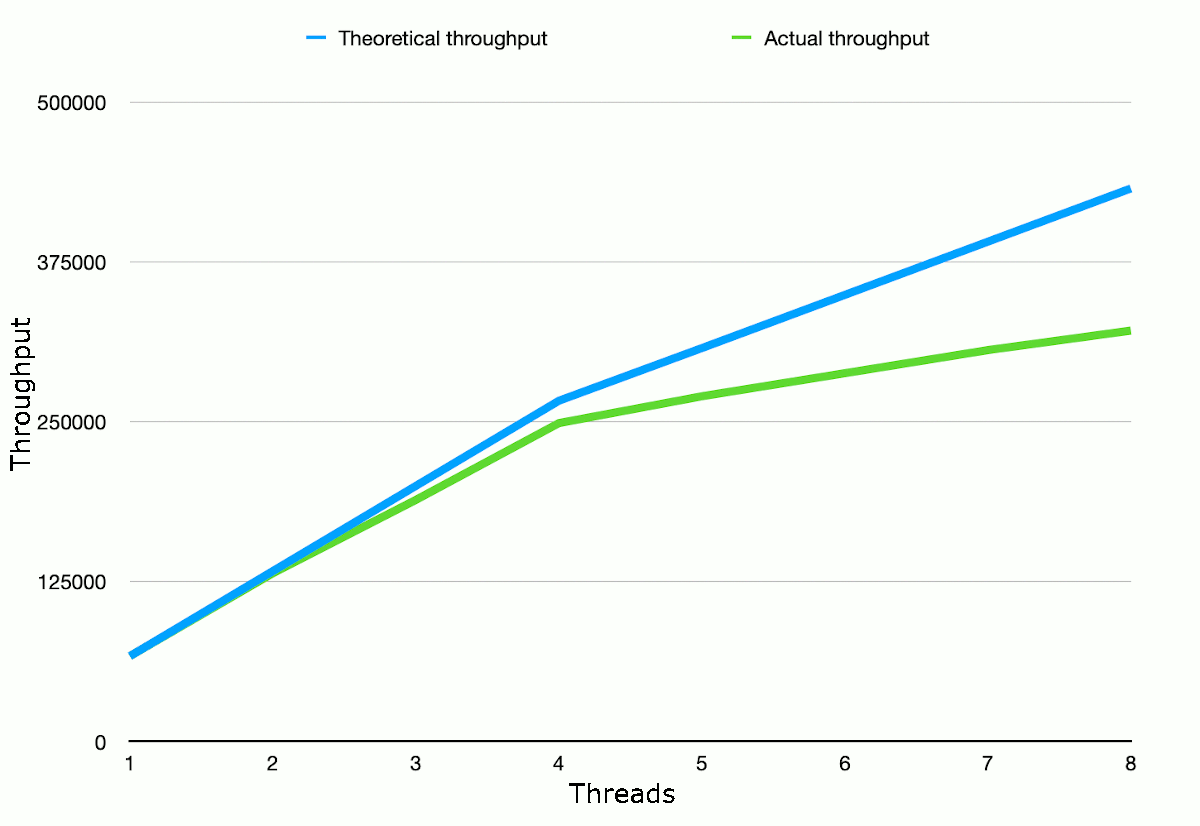
Given the clock frequency ratio of 3.2/2 betwen the M1's high-performance and high-efficiency
cores, and the observed throughput per thread when running on the high-performance cores, we can
estimate a theoretical throughput with all cores maximised by our threads. The graph below
shows that theoretical throughput versus the observed throughput.
Further M1/i7 performance comparisons
In a test of RSA encryption speed
on the M1 vs Intel i7, the M1 performs in the order of 25-30% faster than the i7 in terms of raw performance, but shows
a similar pattern of scalability.
Programs that may show greater speed improvements on the M1 include:
- certain routines that can take advantage of the larger number of registers in ARM vs x86 architecture;
- algorithms that rely on a large number of memopry accesses to arbitrary locations.
(Further information on the above is currently being compiled and will be published to this web site soon.)
If you enjoy this Java programming article, please share with friends and colleagues. Follow the author on Twitter for the latest news and rants.
Editorial page content written by Neil Coffey. Copyright © Javamex UK 2021. All rights reserved.